'2.8.0'Load Trained Models in PyTorch
PyTorch
Deep Learning
Introduction
In this blog post, we’ll explore how to load pre-trained PyTorch models and use them for inference on new images. Pre-trained models are neural networks that have already been trained on large datasets (like ImageNet) and can be used for various computer vision tasks without having to train from scratch.
We’ll walk through the complete process: 1. Loading a pre-trained model from torchvision 2. Preprocessing an input image 3. Running inference to get predictions 4. Interpreting the results
Let’s start by checking our PyTorch version and exploring available models.
Step 1: Loading Pre-trained Models
PyTorch’s torchvision library provides access to many pre-trained models. Let’s first see what models are available, then load a ResNet-101 model that was pre-trained on ImageNet.
['AlexNet',
'AlexNet_Weights',
'ConvNeXt',
'ConvNeXt_Base_Weights',
'ConvNeXt_Large_Weights',
'ConvNeXt_Small_Weights',
'ConvNeXt_Tiny_Weights',
'DenseNet',
'DenseNet121_Weights',
'DenseNet161_Weights',
'DenseNet169_Weights',
'DenseNet201_Weights',
'EfficientNet',
'EfficientNet_B0_Weights',
'EfficientNet_B1_Weights',
'EfficientNet_B2_Weights',
'EfficientNet_B3_Weights',
'EfficientNet_B4_Weights',
'EfficientNet_B5_Weights',
'EfficientNet_B6_Weights',
'EfficientNet_B7_Weights',
'EfficientNet_V2_L_Weights',
'EfficientNet_V2_M_Weights',
'EfficientNet_V2_S_Weights',
'GoogLeNet',
'GoogLeNetOutputs',
'GoogLeNet_Weights',
'Inception3',
'InceptionOutputs',
'Inception_V3_Weights',
'MNASNet',
'MNASNet0_5_Weights',
'MNASNet0_75_Weights',
'MNASNet1_0_Weights',
'MNASNet1_3_Weights',
'MaxVit',
'MaxVit_T_Weights',
'MobileNetV2',
'MobileNetV3',
'MobileNet_V2_Weights',
'MobileNet_V3_Large_Weights',
'MobileNet_V3_Small_Weights',
'RegNet',
'RegNet_X_16GF_Weights',
'RegNet_X_1_6GF_Weights',
'RegNet_X_32GF_Weights',
'RegNet_X_3_2GF_Weights',
'RegNet_X_400MF_Weights',
'RegNet_X_800MF_Weights',
'RegNet_X_8GF_Weights',
'RegNet_Y_128GF_Weights',
'RegNet_Y_16GF_Weights',
'RegNet_Y_1_6GF_Weights',
'RegNet_Y_32GF_Weights',
'RegNet_Y_3_2GF_Weights',
'RegNet_Y_400MF_Weights',
'RegNet_Y_800MF_Weights',
'RegNet_Y_8GF_Weights',
'ResNeXt101_32X8D_Weights',
'ResNeXt101_64X4D_Weights',
'ResNeXt50_32X4D_Weights',
'ResNet',
'ResNet101_Weights',
'ResNet152_Weights',
'ResNet18_Weights',
'ResNet34_Weights',
'ResNet50_Weights',
'ShuffleNetV2',
'ShuffleNet_V2_X0_5_Weights',
'ShuffleNet_V2_X1_0_Weights',
'ShuffleNet_V2_X1_5_Weights',
'ShuffleNet_V2_X2_0_Weights',
'SqueezeNet',
'SqueezeNet1_0_Weights',
'SqueezeNet1_1_Weights',
'SwinTransformer',
'Swin_B_Weights',
'Swin_S_Weights',
'Swin_T_Weights',
'Swin_V2_B_Weights',
'Swin_V2_S_Weights',
'Swin_V2_T_Weights',
'VGG',
'VGG11_BN_Weights',
'VGG11_Weights',
'VGG13_BN_Weights',
'VGG13_Weights',
'VGG16_BN_Weights',
'VGG16_Weights',
'VGG19_BN_Weights',
'VGG19_Weights',
'ViT_B_16_Weights',
'ViT_B_32_Weights',
'ViT_H_14_Weights',
'ViT_L_16_Weights',
'ViT_L_32_Weights',
'VisionTransformer',
'Weights',
'WeightsEnum',
'Wide_ResNet101_2_Weights',
'Wide_ResNet50_2_Weights',
'_GoogLeNetOutputs',
'_InceptionOutputs',
'__builtins__',
'__cached__',
'__doc__',
'__file__',
'__loader__',
'__name__',
'__package__',
'__path__',
'__spec__',
'_api',
'_meta',
'_utils',
'alexnet',
'convnext',
'convnext_base',
'convnext_large',
'convnext_small',
'convnext_tiny',
'densenet',
'densenet121',
'densenet161',
'densenet169',
'densenet201',
'detection',
'efficientnet',
'efficientnet_b0',
'efficientnet_b1',
'efficientnet_b2',
'efficientnet_b3',
'efficientnet_b4',
'efficientnet_b5',
'efficientnet_b6',
'efficientnet_b7',
'efficientnet_v2_l',
'efficientnet_v2_m',
'efficientnet_v2_s',
'get_model',
'get_model_builder',
'get_model_weights',
'get_weight',
'googlenet',
'inception',
'inception_v3',
'list_models',
'maxvit',
'maxvit_t',
'mnasnet',
'mnasnet0_5',
'mnasnet0_75',
'mnasnet1_0',
'mnasnet1_3',
'mobilenet',
'mobilenet_v2',
'mobilenet_v3_large',
'mobilenet_v3_small',
'mobilenetv2',
'mobilenetv3',
'optical_flow',
'quantization',
'regnet',
'regnet_x_16gf',
'regnet_x_1_6gf',
'regnet_x_32gf',
'regnet_x_3_2gf',
'regnet_x_400mf',
'regnet_x_800mf',
'regnet_x_8gf',
'regnet_y_128gf',
'regnet_y_16gf',
'regnet_y_1_6gf',
'regnet_y_32gf',
'regnet_y_3_2gf',
'regnet_y_400mf',
'regnet_y_800mf',
'regnet_y_8gf',
'resnet',
'resnet101',
'resnet152',
'resnet18',
'resnet34',
'resnet50',
'resnext101_32x8d',
'resnext101_64x4d',
'resnext50_32x4d',
'segmentation',
'shufflenet_v2_x0_5',
'shufflenet_v2_x1_0',
'shufflenet_v2_x1_5',
'shufflenet_v2_x2_0',
'shufflenetv2',
'squeezenet',
'squeezenet1_0',
'squeezenet1_1',
'swin_b',
'swin_s',
'swin_t',
'swin_transformer',
'swin_v2_b',
'swin_v2_s',
'swin_v2_t',
'vgg',
'vgg11',
'vgg11_bn',
'vgg13',
'vgg13_bn',
'vgg16',
'vgg16_bn',
'vgg19',
'vgg19_bn',
'video',
'vision_transformer',
'vit_b_16',
'vit_b_32',
'vit_h_14',
'vit_l_16',
'vit_l_32',
'wide_resnet101_2',
'wide_resnet50_2']Step 2: Image Preprocessing
Before we can use our model for inference, we need to preprocess the input image. Pre-trained models expect images in a specific format:
- Resize and crop: Images should be 224x224 pixels
- Convert to tensor: Transform from PIL Image to PyTorch tensor
- Normalize: Apply the same normalization that was used during training (ImageNet statistics)
The normalization values (mean and std) are specific to ImageNet and help the model perform better.
AlexNet(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(6, 6))
(classifier): Sequential(
(0): Dropout(p=0.5, inplace=False)
(1): Linear(in_features=9216, out_features=4096, bias=True)
(2): ReLU(inplace=True)
(3): Dropout(p=0.5, inplace=False)
(4): Linear(in_features=4096, out_features=4096, bias=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)Let’s load our dog image and apply the preprocessing transformations:

Step 3: Model Inference
Now we’re ready to run inference! Here’s what we need to do:
- Set model to evaluation mode: This disables dropout and batch normalization updates
- Add batch dimension: Models expect batched inputs, so we add a dimension
- Run inference: Use
torch.inference_mode()for efficiency and to disable gradient computation - Get predictions: The model outputs raw logits (unnormalized scores) for each class
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-1.980906..2.3785625].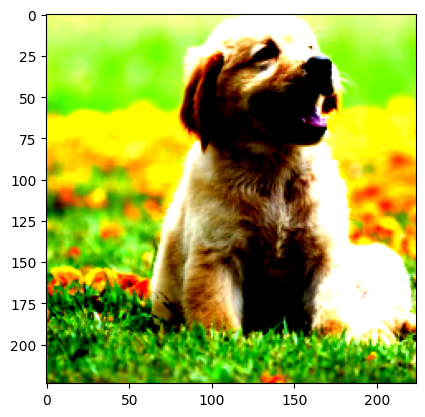
Step 4: Interpreting Results
The model outputs raw logits (scores) for each of the 1000 ImageNet classes. To make sense of these predictions, we need to:
- Load class labels: Get the human-readable names for each class
- Convert to probabilities: Apply softmax to get probabilities that sum to 1
- Find top predictions: Sort by probability to see the most likely classes
Let’s see what our model thinks the dog image contains!
[('golden retriever', 8.721056938171387),
('Labrador retriever', 5.845145225524902),
('Brittany spaniel', 5.5844011306762695),
('clumber, clumber spaniel', 2.9428038597106934),
('Sussex spaniel', 2.8260412216186523)][('golden retriever', 0.7772852182388306),
('Labrador retriever', 0.04381147027015686),
('Brittany spaniel', 0.03375577926635742),
('clumber, clumber spaniel', 0.0024050103966146708),
('Sussex spaniel', 0.0021399694960564375)]Summary
In this tutorial, we’ve successfully:
- Loaded a pre-trained ResNet-101 model from torchvision
- Preprocessed a dog image with the correct transformations
- Ran inference to get predictions from the model
- Interpreted the results by converting logits to probabilities and finding the top predictions
The model correctly identified the image as containing a dog breed, demonstrating how pre-trained models can be used for image classification without any additional training. This approach is particularly useful when you have limited data or computational resources, as you can leverage models that have already learned rich visual features from large datasets like ImageNet.
Key Takeaways:
- Pre-trained models save time and computational resources
- Proper preprocessing is crucial for good results
- Models output raw logits that need to be converted to probabilities
- The
torch.inference_mode()context manager is more efficient thantorch.no_grad()for inference
You can now use this same process with any pre-trained model from torchvision for your own image classification tasks!